Basop Encoder: Stereo DTX Front VAD Flag Mismatch
Basic info
I do not have specific SHA for the initial analysis. The commit for both was from April 3rd. However I have tested some of the items with these versions:
- Float reference:
- Fixed point:
- Encoder (fixed): 1ccc3c58
- Decoder (fixed):
Bug description
The front VAD flag decisions were investigated for floating point and fixed point code outputs for low bitrate (13.2kbps) Stereo DTX with 71 test items. Most of the items contain background noise of different versions (such as train station or office). Some test items contain both speech and background noise.
The percentage of frames with different front VAD flags (float vs fixed) for each test item is presented:

The highest difference is 6.5% for a car sound item without speech. I have plotted the difference between the left channels of the outputs along with FrontVAD difference:
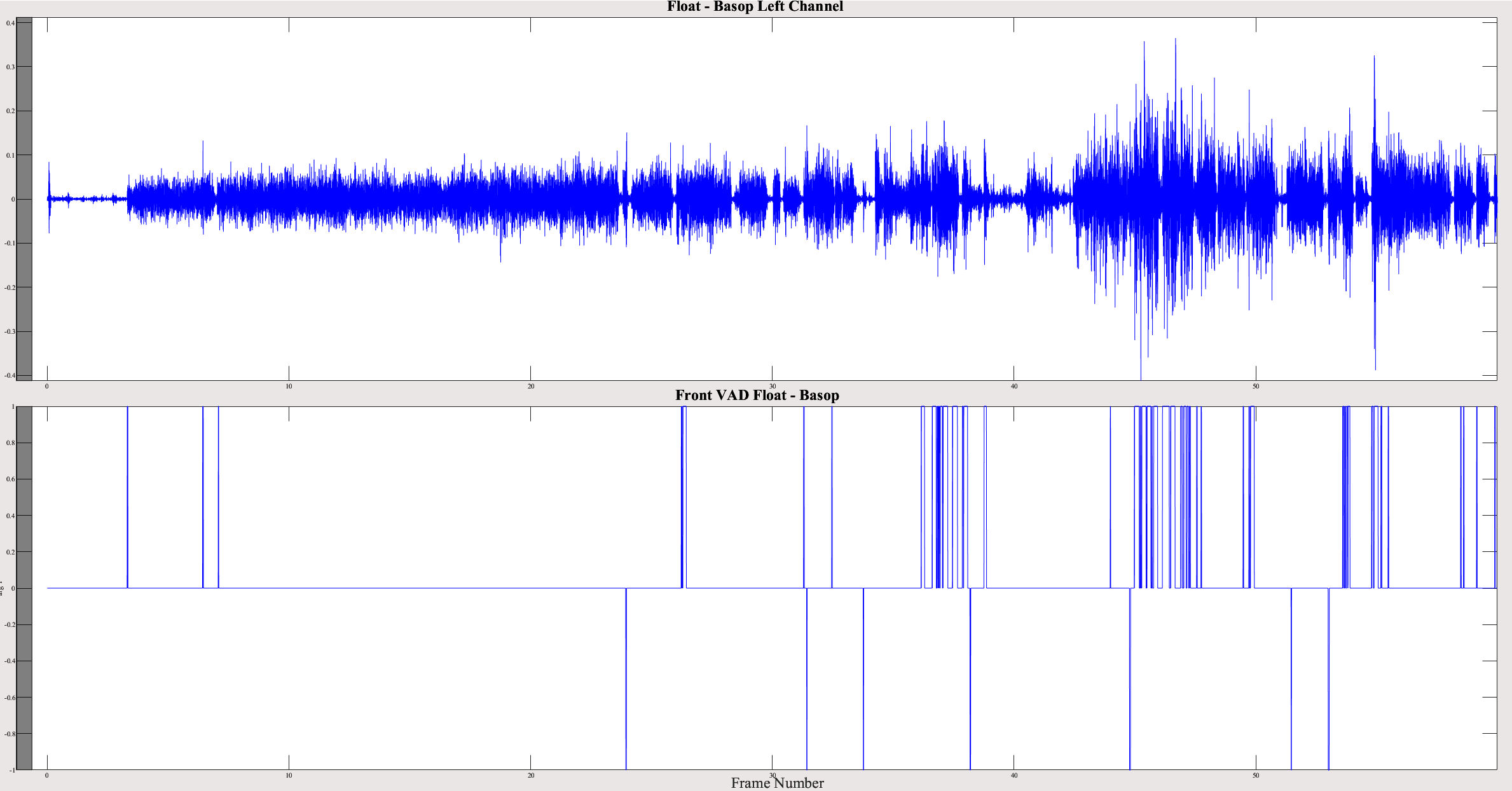
The different frontVAD decisions affect the whole signal and the outputs sound very different. There is already an open issue about this specific item: #1410 (comment 69661)
For a speech+background item with 2.4% difference, the plots look like this:
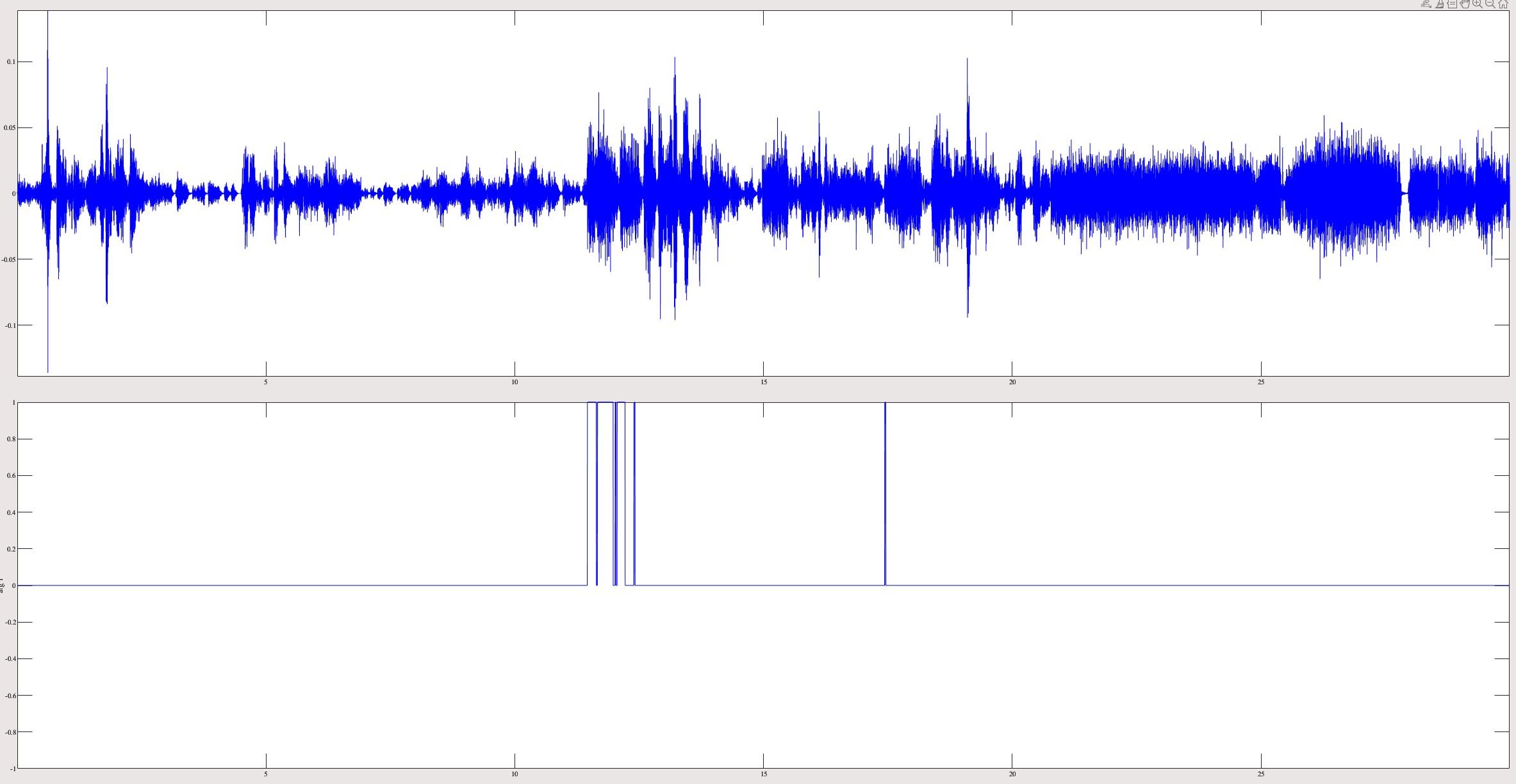
The difference after 10 seconds causes fixed point suppressing the train sound in the background.
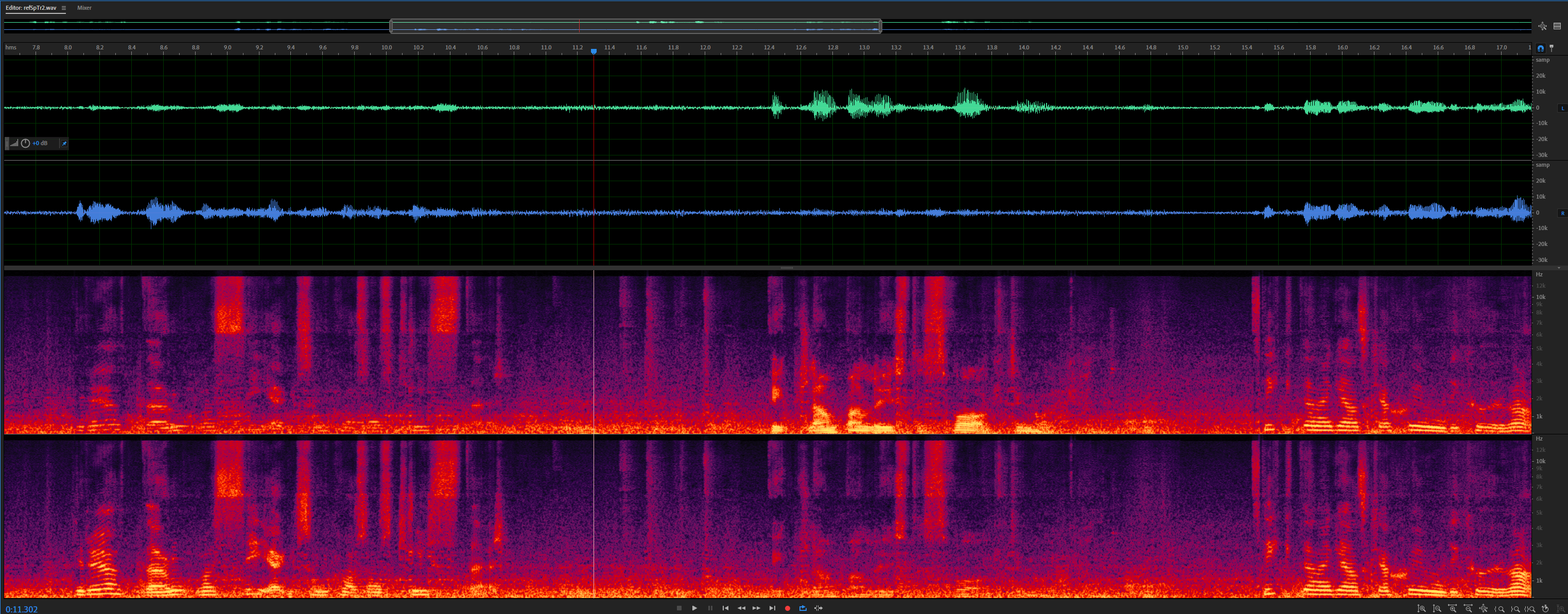
Floating point:
Fixed:
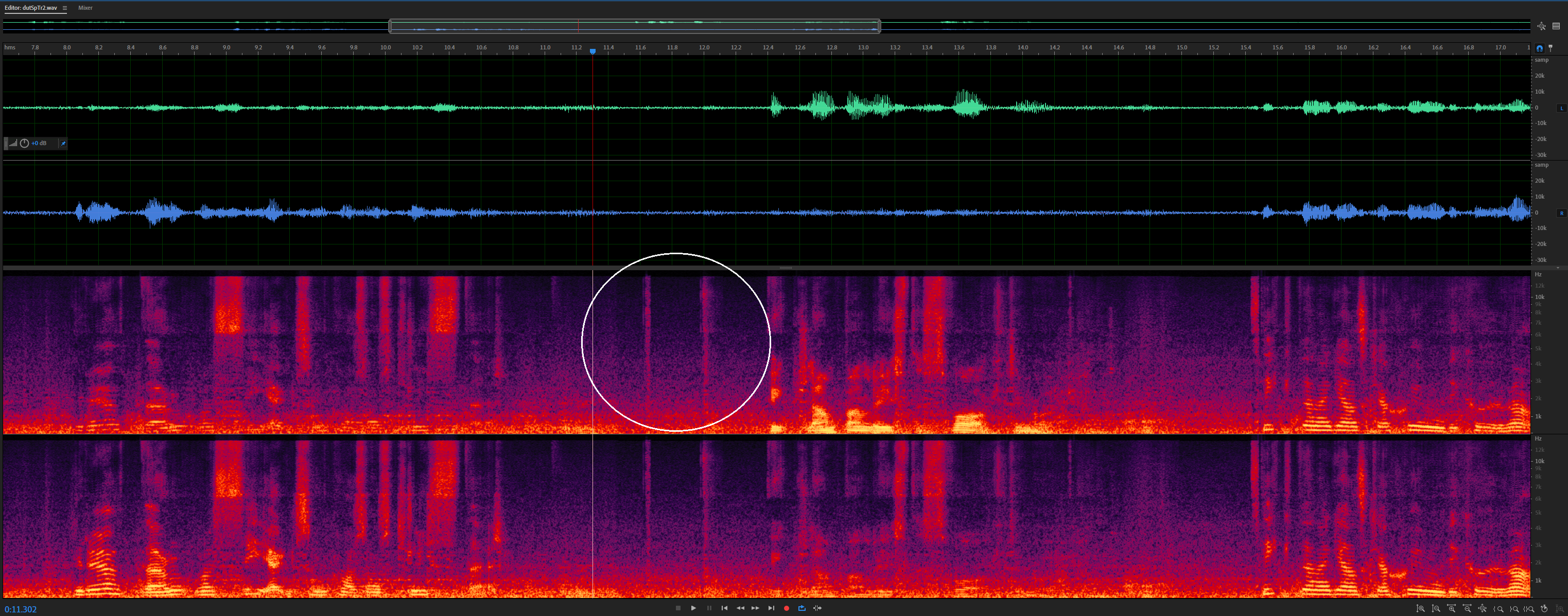
For the same item, there is an energy increase in higher frequencies around 17 seconds, where frontVAD differs.
Ways to reproduce
Box folder: ...\Box_EXTERNAL_IVAS_BASOP_VERIFICATION\issues\issue-1487
./IVAS_cod_ref.exe -dtx -stereo 13200 32 spTr2.wav bitref
./IVAS_dec_ref.exe stereo 32 bitref refSpTr2.wav
./IVAS_cod.exe -dtx -stereo 13200 32 spTr2.wav bit
./IVAS_dec_ref.exe stereo 32 bit dutSpTr2.wavThere are a few speech+background noise items where frontVAD difference results in distortion or spectral differences in between speech segments.
Issue is labeled as medium since for the test items mentioned here, the differences mainly occur for background sound segments, and not the speech segments.